Python字节码解混淆之反控制流扁平化
前言
上次打NISCCTF2019留下来的一道题,关于pyc文件逆向,接着这道题把Python Bytecode解混淆相关的知识和工具全部过一遍。同时在已有的基础上进一步创新得到自己的成果,这是下篇,更近一步进行还原混淆过的pyc文件。
图表示法
目前可以见到最多的解混淆或者去花指令的手段类似于对于指令的匹配替换,甚至于可以说上一篇中的活跃代码分析也是带执行流分析的简单替换过程。但如果我想构建一个对于某种混淆方式的通用解法,只是工作于指令级别始终不够方便。那么需要一种新的方式去处理这些指令。
在这里选用一种基于有向图的表示法,也即在执行流跳转的位置进行分割,使指令之间成块,相互之间用箭头相关联。如下图:
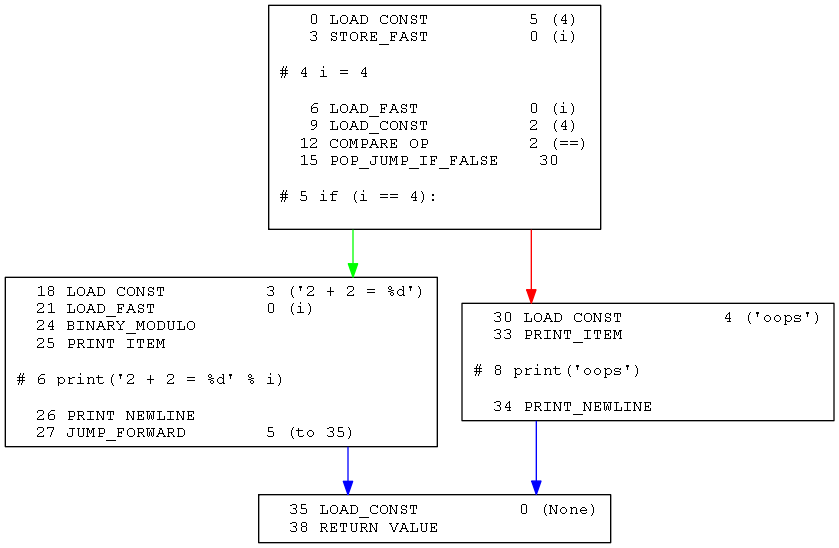
有了这种表示法之后就可以方便的在独立的块之间进行遍历和处理。
Bytecode graph
这个工具来自这里,实现了基本的Python字节码到图表示的转换过程,但是相比起来功能较为单薄。
上一篇中把恶意指令全部NOP掉了,现在想把NOP指令用这个库全部去除,首先尝试调用API画出所有函数的图:
1 | import bytecode_graph |
结果崩溃了:
1 | Traceback (most recent call last): |
查看源码发现是渲染模块里获取block的函数写的时候没有考虑到一个corner case,修复之后成功生成图像:
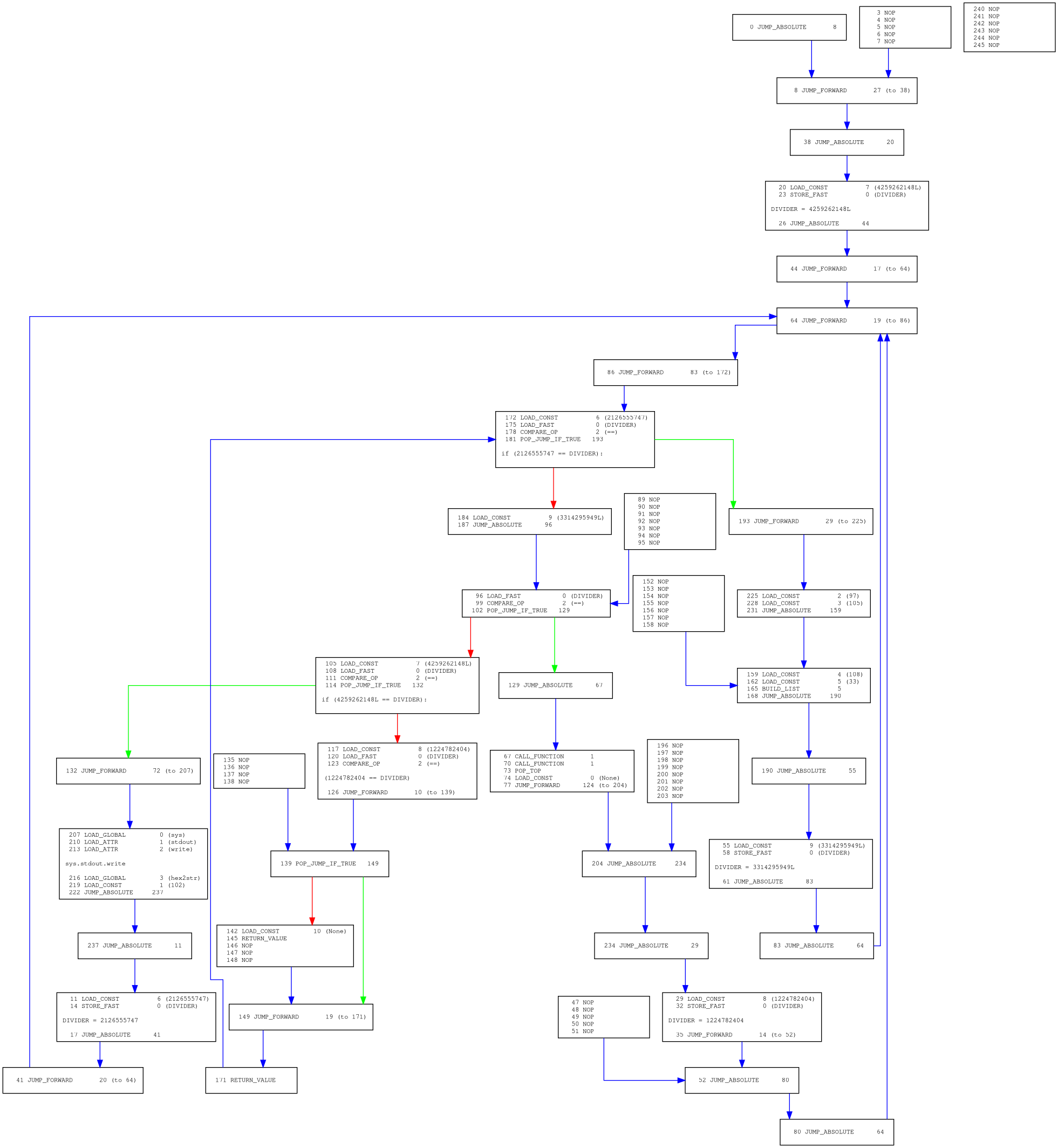
首先观察执行流可以很明显的看出是进行过控制流扁平化处理的,然后尝试阅读文档去除多余的NOP分支。
去除NOP的代码:
1 | def remove_nop_inner(co): |
再次运行然后再次崩溃:
1 | Traceback (most recent call last): |
这个错误就很有意思了,和之后成功还原仍然不能使用uncompyle6得到源码有关。都是在对co_lnotab这个部分的解析中出现了错误导致的崩溃。
Python通过co_lnotab将字节码和源码行数对齐,服务于源码调试。co_lnotab中的数据两字节为一组,分别是字节码的增量偏移和源码的增量偏移。
1 | import marshal |
也即都从0开始计算,首先字节码增加了12条指令,源码就到了第2行,这样不断递增得到的对应关系。
1 | dis.dis(c.co_code) |
然而这样的对应关系在修改了指令成为NOP之后便没有意义,因为从带参数的指令变成不带参数的指令定然会导致字节码偏移计算出错。更何况这个样本的pyc文件有的函数的co_lnotab是残缺的,便会导致尝试解析它的过程失败。然而不巧这个库和uncompyle6都是会解析的。
但即使是这样,这款库作为图的生成器,自带的指令解析和引用解析都不错,仍旧写出图生成脚本予以采用。并对之前的补丁操作提出了pr。
1 | import bytecode_gra as bytecode_graph |
Bytecode simplifier
这个比之前那个更加强大,来自于这篇博客。
这个简化器原本是为了针对PjOrion解混淆而开发的,说来也是有意思,我这个样本被命中了PjOrion v2的特征签名。
在分析上它同样使用遍历执行流的方式得到实际字节码并分离成一个一个基本块,特指只有一个入口和一个出口的一连串指令
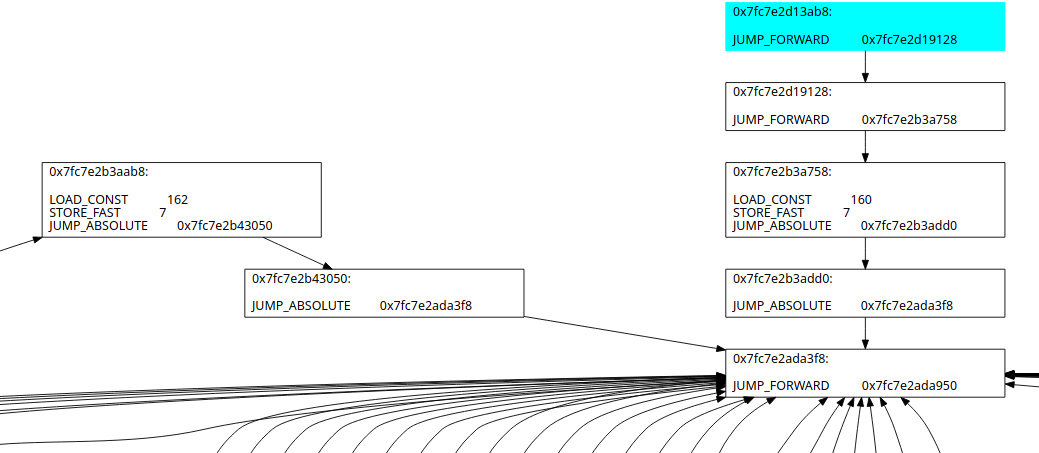
可以看到完全无视之前生成的NOP。
在表示上直接使用networkx.DiGraph组织有向图,提供完整API,在类似if分支时正确分支为explicit属性的边,失败分支是implicit属性的边。正常的跳转的边都是explicit的。
自带的解混淆功能
Forwarder elimination
forwarder定义为只由一条跳转语句构成的基本块,只是转移了执行流没有任何有用操作。

黄色高亮的基本块就是一个forwarder,下图是去除以后。
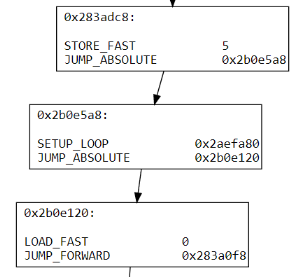
Basic block merging
一个基本块可以被它的父基本块合并,当且仅当它只有这一个父基本块,且它的父基本块只有它一个子基本块。
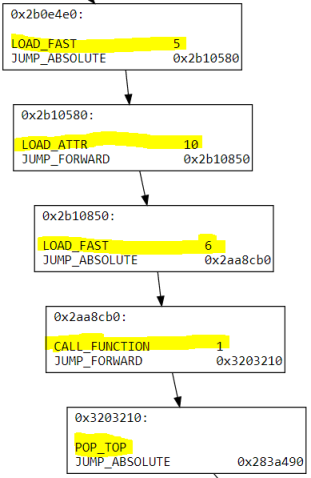
高亮的基本块都能合并成为一个基本块,既然没有用,那么控制流转移指令被全部删除。

具体实现可以参考simplifier.py里的源码。
自己写的反控制流扁平化功能
首先还是在不添加简化流程的情况下运行,程序再次崩溃:
1 | INFO:simplifier:43 basic blocks eliminated |
分析之后发现是在forwarder elimination之后把有入口点属性的基本块给消除了。修改源码在修改之后传递属性即可,同样提交pr。
终于来到编写部分,在这里阐明控制流扁平化之后在本样本的特征:
入口点指定好第一个执行的块的常量然后进入分发基本块链
在分发基本块链中不断查找,只有在常量相等时进入正确分支执行对应基本块,否则进入失败分支继续查找
在实际执行基本块结尾指定下一块实际基本块的常量值
举例如下:
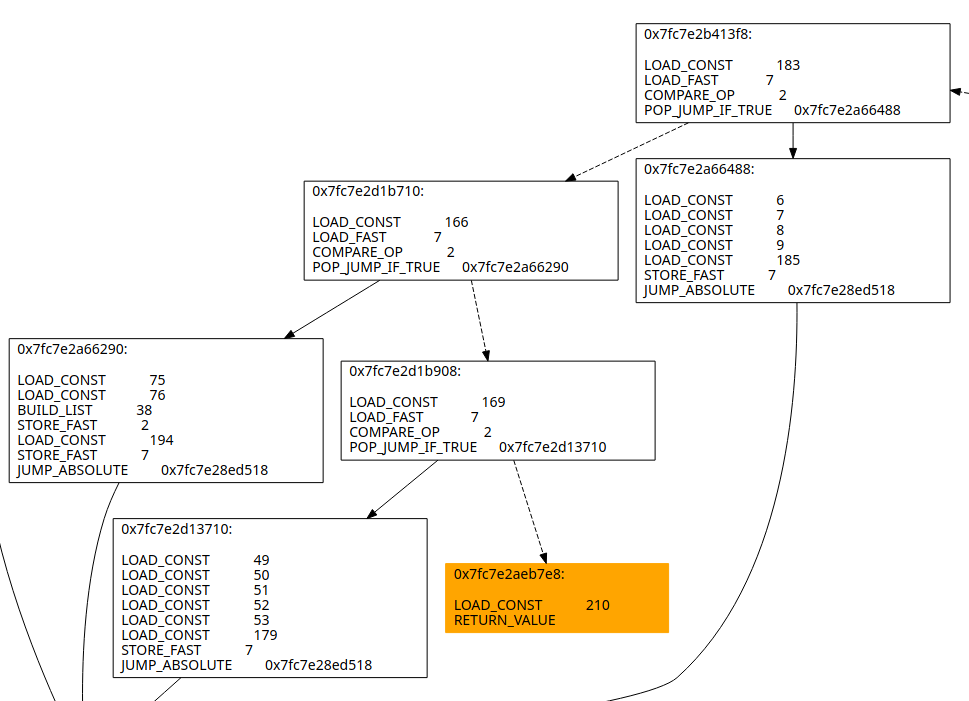
那么整个过程可以分成几步:
沿着分发基本块遍历得到分发关系,再找到实际基本块的尾端确认下一基本块的常量,之后配对得到实际关系
再修改配对的基本块之间的执行流,还原他们的先后执行次序
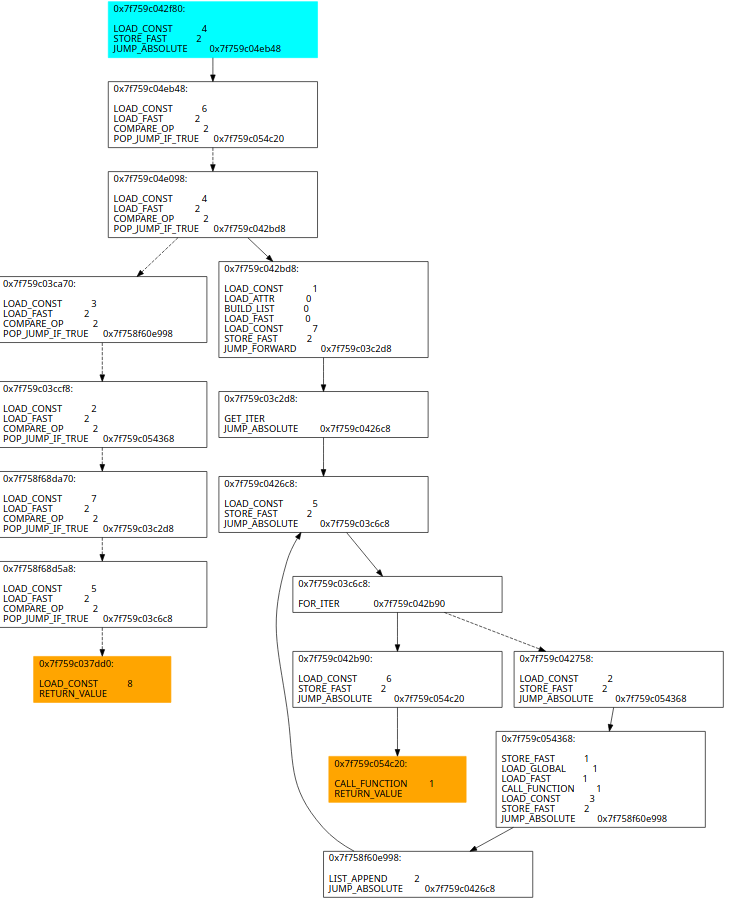
对入口点设置的常量的对应实际基本块设置成为入口点
把分发基本块链和入口点全部删除
把所有基本块尾部存在的设置常量的指令删除
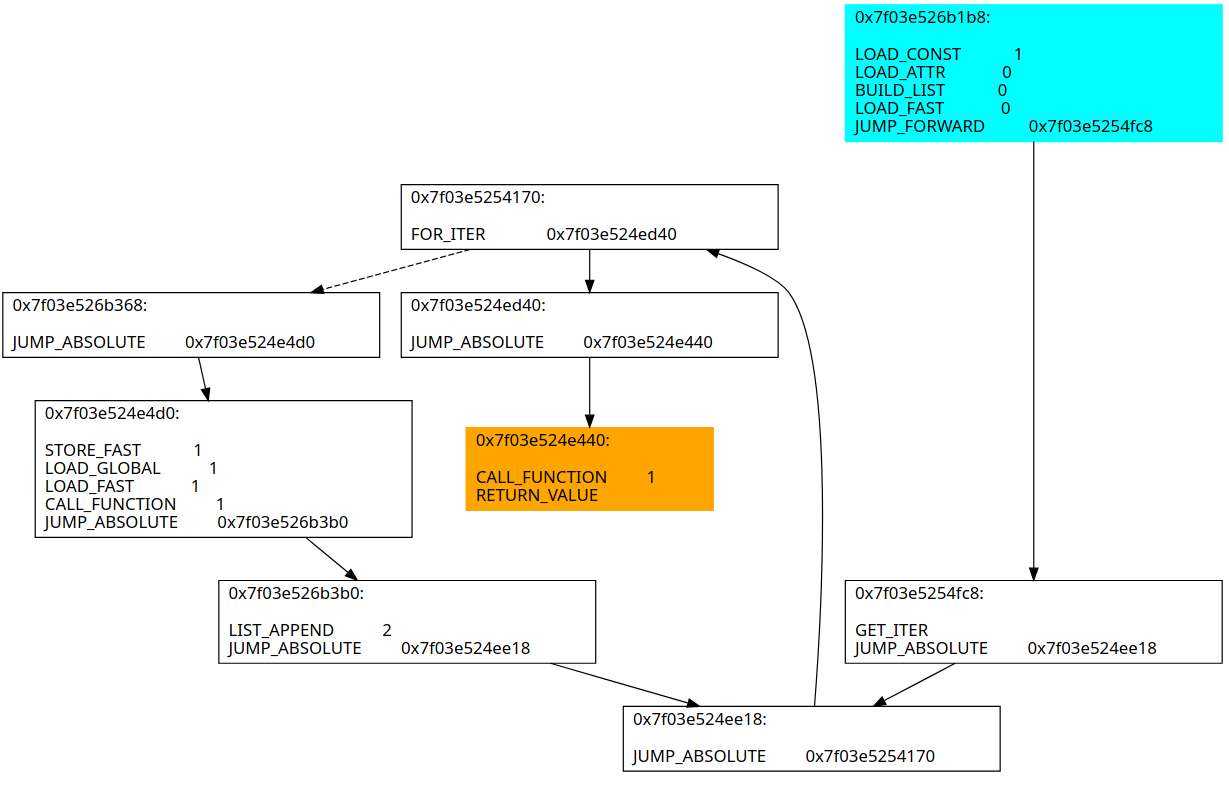
可以看到原来打乱的控制流还原了,但是基本块之间还是有些琐碎,怎么办呢?
很简单,再跑一次forwarder elimination和merge blocks就行了!
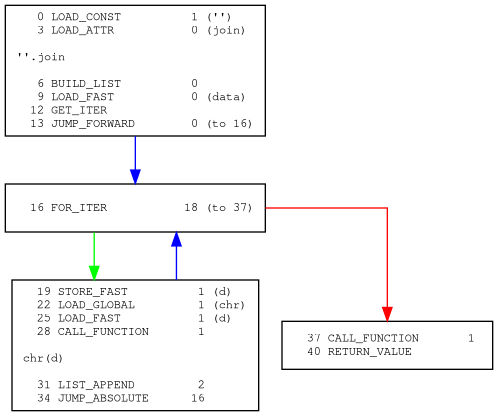
可以看到这样就已经还原到近似于CPython生成的字节码了。虽然因为之前说过的原因用不了uncompyle6,但是可以用unpyc进行反编译可以得到:
1 | def str2hex(string): |
虽然有反编译出来的结果有问题,但还是不错了的。
小结
使用基于图的表示法成功针对控制流平坦化进行了还原。虽然针对ollvm的解混淆已经有了,但是针对Python字节码的还没看到,所以也算是做出了自己的成果。
本人投稿至安全客平台。
原文来自安全客,原文链接: https://www.anquanke.com/post/id/185482
声明:本文经安全客授权发布,转载请联系安全客平台。