CUMTCTF2019决赛-逆向题WP
Hook
出题点在题目上就已经很清楚了,意思就是修改了题目中的函数进行了替换。首先查看main函数:

正常的读去用户输入然后限定长度是19个字符,再走过黄标的函数之后经过sub_401240函数的检验。
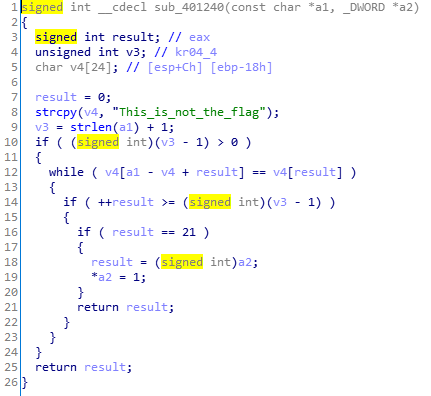
函数中的”fake flag”字样表明这并不是真正的检查函数,于是仔细看下之前的黄标函数。
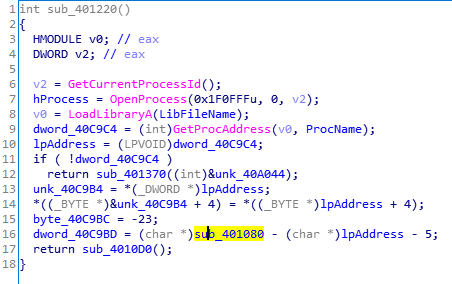
里面开启内存的可写权限然后替换WriteFile函数为图中的黄标函数,进入黄标函数就可以看到真正的检查函数sub_401000。

逆向其中的核心加密流程写出对应的解密脚本,其中第一位的信息在加密后的数据中并没有包含。先看看解密脚本。
1 | target = [97, 108, 121, 103, 107, 72, 109, 48, 127, 95, 126, 49, 83, 104, 123, 70, 109, 110, 125] |
跑完之后得到的结果是alag{Ho0k_w1th_Fun,其中第一位不难猜出就是f。
Cracker
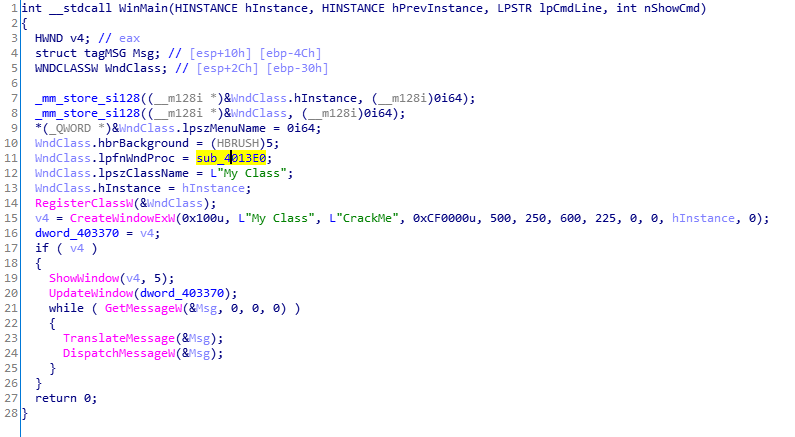
Windows的窗口程序管理查看WinMain函数内容,发现窗口处理函数为sub_4013E0。
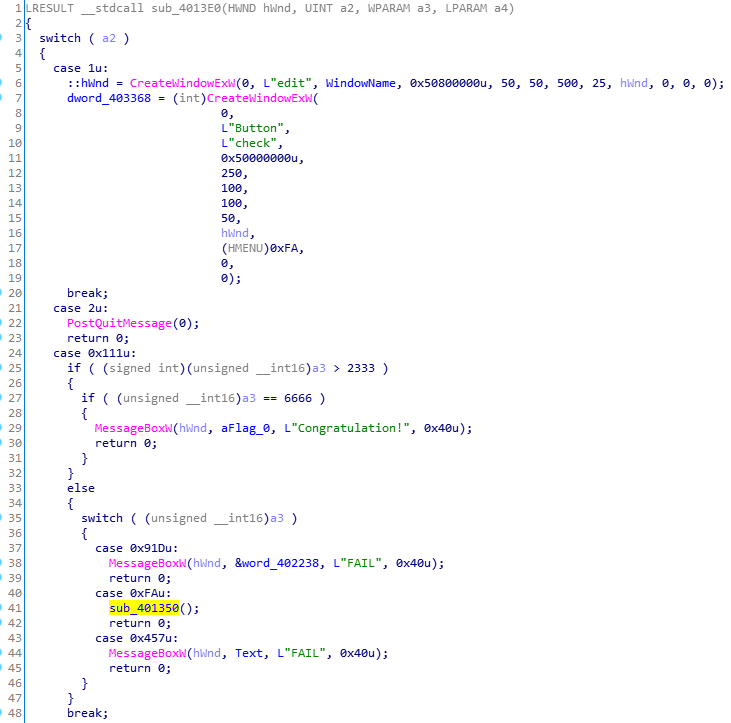
这个函数是一个很典型的按照接受到的事件进行分发处理的函数,对应的函数是黄标的sub_401350。其中进行加密和检验的函数是sub_401200。
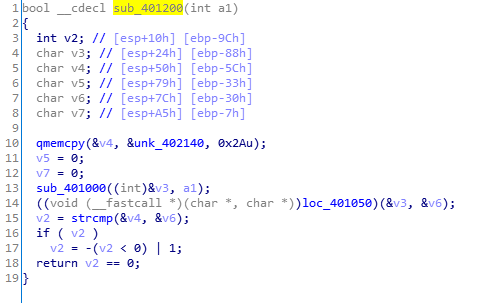
在这个函数中用户输入经过两个函数分别处理,也就是说变换了两次,先看第一次。
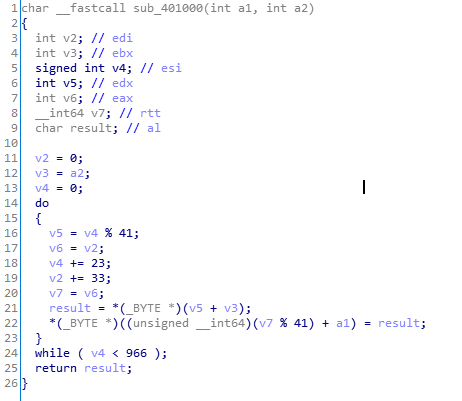
简单的下标计算进行变换,再看第二个,
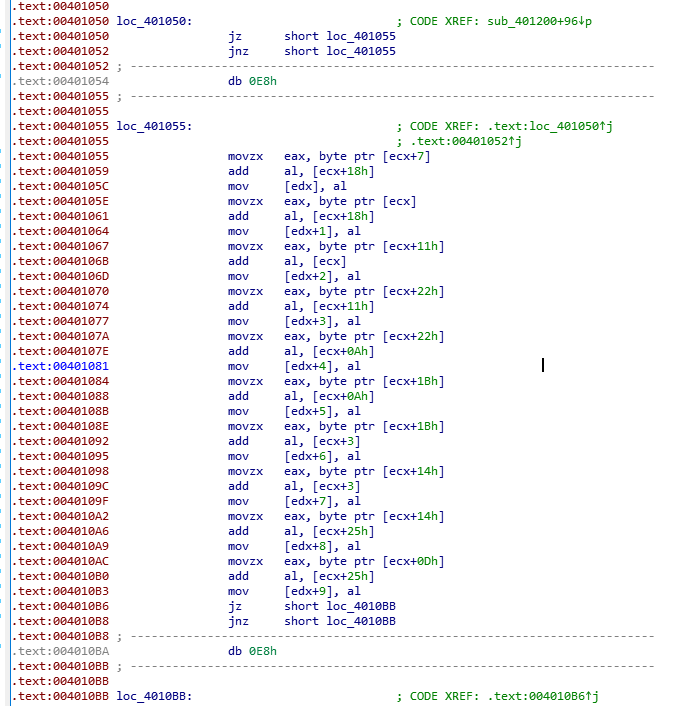
这个函数中间有无用的数据,用IDA跳过之后重新转化成反编译就能看到了。阅读汇编代码,显然是把上个函数处理完的数组中的某两项相加得到新的一项然后和加密过的数据进行比较。
那么核心流程就是输入数据的两次变换后要求和加密数据相等,于是梳理出对应关系编写脚本进行求解。
1 | from z3 import * |
Block
Block这道题同样是Windows的窗体程序,其中最引人瞩目的是sub_401060的这一段。

在这里创建了自己作为子进程然后进行调试,检查得到无效的机器码执行就把对应的位置+2的一段内存异或上0x76,这就是它变换自己程序代码的过程。利用Python脚本解密完之后得到对应的反编译代码如下。
加密逻辑就是简单的异或,直接编写脚本即可解密求解。
Cynic
第一步先根据文章修改function size。
文章链接:https://www.dllhook.com/post/217.html
将这个标记位修改完成之后,我们就能正常查看整个函数和进行F5反编译了,但是速度很慢。
耐性等待就好,只反编译一次就够用了。
反编译完成之后我们可以看到,基础的输入输出,判断长度和运算都没变,而且确实没有了VM结构。反而多了一堆异或运算。那么我们先确定这些异或运算会不会影响我们的输入输出。
随便点击几个可以发现他是迭代异或下去的,然而数据在我们对比的数据后门很多,那么就说明这是不影响我们输入输出的东西,就可以当做垃圾代码除掉了。(先将F5得到的代码全选保存成TXT文档)
1 | import struct |
除去之后就只剩这些与运算相关的数据了,但是这里因为他用的全局变量来存储的flag字符串,所以我们没有办法吧byte_xxxxx合并为一个数组,那么我们就用正则去匹配合并好了,同样也是只有简单运算,合并好了之后倒着运算一遍就出来结果了。
1 | import struct |
MBR
首先查看文件类型发现这可能是一个MBR主引导扇区文件。运行一下这个程序:
1 | qemu-system-i386 -drive format=raw,file=main.bin |

然后用32位IDA的16-bit模式打开main.bin,发现汇编代码,找到标志检查位,代码分析结果如下(注释):
1 | seg000:0066 cmp byte ptr ds:7DC8h, 13h |
根据之前做过的CSAW逆向题遇到过这种模式的题目,照着思路调试了一遍
模拟对应的指令操作写出解密脚本:
1 | #!/usr/bin/env python |
Morse
终于见到了一道Mobile逆向题。
打开之后随便点击几下屏幕,偶尔绿偶尔红,Logcat也会有输出,猜测是根据点击屏幕的时间长短来处理。
用C++写的native activity,manifest里什么东西都没有,dex里只有support的包,逻辑全都在libnative.so里。
看一下导入表,大概率是使用EGL去绘制一些东西,以及gettimeofday来计时。
看一下导出表,入口在android_main,注册了2个函数,sub_F3ECBF70看起来是onCreate,初始化EGL,sub_F3ECC154看起来是onTouch做check。
猜测:AMotionEvent_getAction拿到的是onKeyDown和onKeyUp的事件,分别调用gettimeofday,拿到按压的持续时长,并且按下时(v3+40)=0,会将屏幕主动调整为颜色A。大于0.2ms是1,小于0.2ms是0,这与题目说的Morse很像。之后index = 7 ((v3 + 52) % 4) + (v3 + 52) / 32与byte_F3ED0008[index]做xor,最后bit相同时候认为本次check成功,(v3+40)=0颜色调整为A,byte_F3ED0008[index] >>= 1, (v3 + 52)++,一旦(v3 + 52)大于224,就认为全部判定成功。若本次判定失败,则重置(v3 + 52) = 0,设定颜色*(v3 + 44) = 0x3F800000为颜色B。最后,如果上文一直没有return,就会复制一段rodata到bss段上,将byte_F3ED0008[28]初始化。
综上,(v3 + 52)最初为0,经过224次变化,每次变化会加一,而index = 7 ((v3 + 52) % 4) + (v3 + 52) / 32,dump出byte_F3ED0008[index]和index的序列,即可还原出flag的bit顺序。
之后遇到一个小问题,还原出来的224bit = 28 8bit = 327bit,而0对应0还是1,所以共有4种组合,最后得到32个字符最合理。
1 | data = [0xA7,0xD6,0x61,0xB5,0x6E,0xBB,0xBA,0xE3,0xA9,0xDD,0xC4,0x77,0x6F,0xEE,0xEC,0xFF,0x62,0xC3,0xCF,0xDA,0x53,0xCE,0xFF,0x71,0x71,0x14,0xFF,0xF2] |